谷歌位于英国的DeepMind子公司的最新研究表明,深度神经网络具有理解场景,以紧凑格式表现的能力,然后“想象”从网络的角度来看,同一场景看起来会是什么样子前面看过。
人类擅长这一点。如果显示一张只有前面三条腿可见的桌子的照片,大多数人直观地知道,桌子可能在相反一侧有第四条腿,而桌子后面的墙可能与他们可以看到的部分颜色相同。通过练习,我们可以学习从另一个角度来描绘场景,同时考虑透视,阴影和其他视觉效果。
由Ali Eslami和Danilo Rezende领导的DeepMind团队开发了基于深度神经网络的软件,这些软件具有相同的功能 – 至少适用于简化的几何场景。鉴于虚拟场景的一些“快照”,称为生成查询网络(GQN)的软件使用神经网络来构建该场景的紧凑数学表示。
然后,它使用该表示从新的角度呈现房间的图像 – 这是网络以前从未见过的视角。
研究人员并没有对他们将呈现在GQN中的环境的任何先前知识进行硬编码。人类有多年的经验看待现实世界的物体。DeepMind网络通过检查来自类似场景的一系列图像来开发自己的类似直觉。
“当我们看到它可以做透视和遮挡以及照明和阴影等事情时,最令人惊讶的结果之一是,”Eslami在周三接受电话采访时告诉我们。“我们知道如何编写渲染器和图形引擎,”他说。然而,DeepMind软件的卓越之处在于程序员
没有 试图将这些物理定律硬编码到软件中。相反,Eslami说,该软件开始时是一张空白的平板,能够“通过查看图像来有效地发现这些规则。”
这是深度神经网络令人难以置信的多功能性的最新演示。我们已经知道如何使用深度学习对图像进行分类,在Go上获胜,甚至可以玩Atari 2600游戏。
现在我们知道他们对三维空间的推理具有非凡的能力。
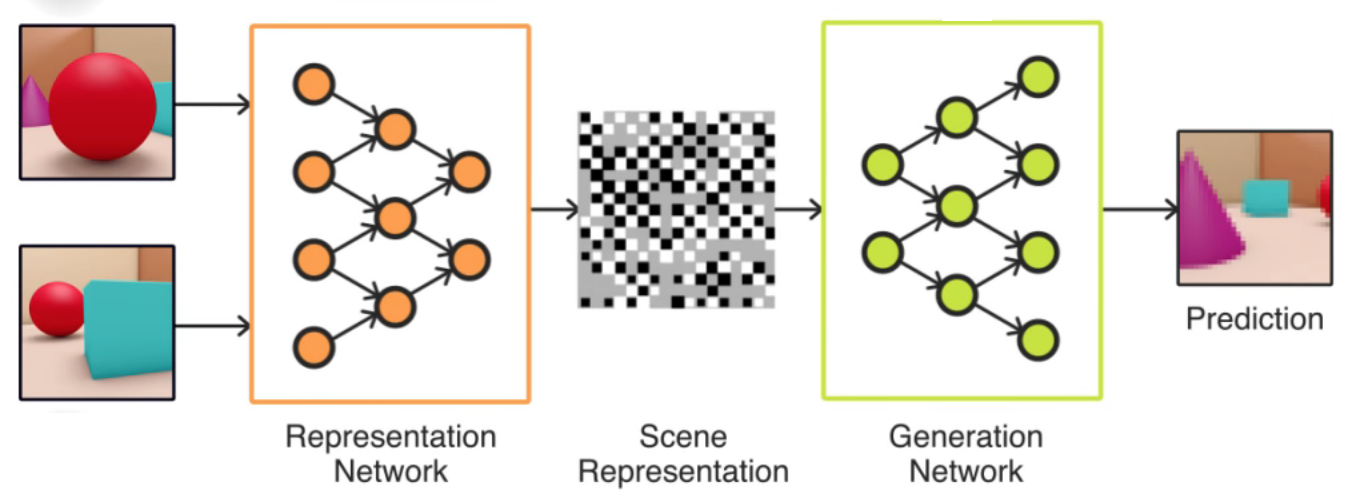
DeepMind的生成查询网络如何工作
以下是DeepMind提供的一个简单示意图,可帮助您直观了解GQN的组合方式:
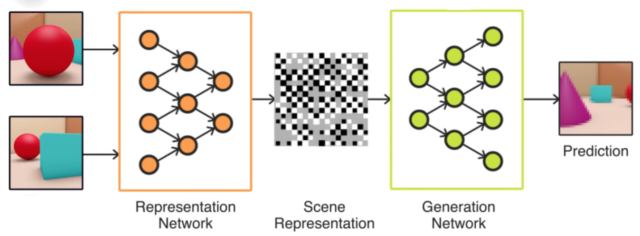
在引擎盖下,GQN实际上是连接在一起的两个不同的深层神经网络。在左边,表示网络接收表示场景的图像集合(连同关于每个图像的相机位置的数据)并将这些图像压缩成场景的紧凑数学表示(基本上是数字的矢量),作为整个。
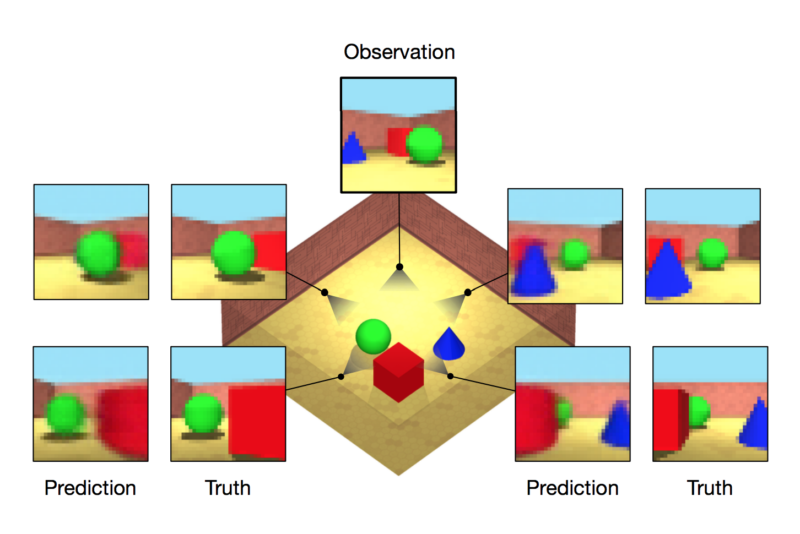
然后,生成网络的任务就是逆转这一过程:从表示场景的矢量开始,接受摄像机位置作为输入,并生成一个图像,表示从该角度看场景的样子。
显然,如果生成网络被赋予相应于其中一个输入图像的相机位置,则它应该能够再现原始输入图像。但是该网络也可以与其他相机位置一起提供 – 网络从未见过对应图像的位置。GQN能够从这些位置生成图像,与来自相同位置的“真实”图像非常匹配。
“这两个网络都是以端到端的方式联合训练的,”DeepMind论文称。
该团队使用随机梯度下降的标准机器学习技术来迭代地改进两个网络。该软件将一些训练图像送入网络,生成输出图像,然后观察该图像与预期结果的差异。传统的神经网络使用外部提供的标签来判断输出是否正确,而GQN的训练算法使用场景图像作为表示网络的输入,
并作为判断发电网络输出是否正确的一种方法。
如果输出与期望的图像不匹配,则软件反向传播错误,更新数千个神经元上的数字权重以改善网络的性能。然后,软件多次重复该过程,并且在每次传递时,网络在获得输入和输出图像以匹配方面会更好一些。
“你可以把它看作是两个相互连接的漏斗,这样瓶颈就可以连接到中间,”Eslami告诉Ars。“因为瓶颈很紧张,两个网络学会一起工作,以确保现场的内容紧密交流。”
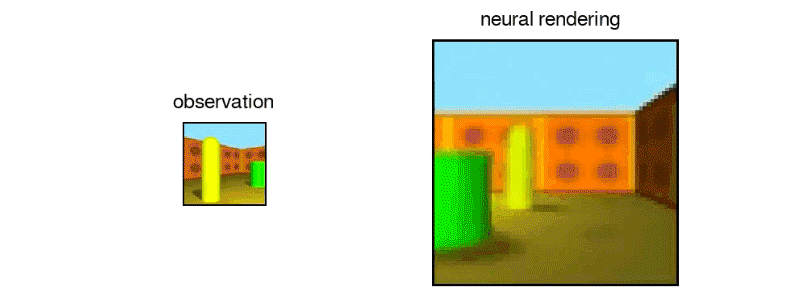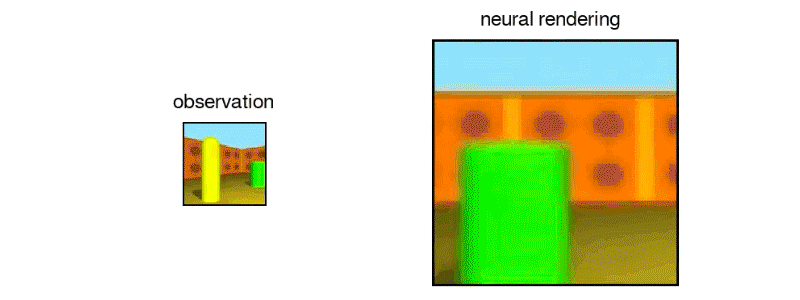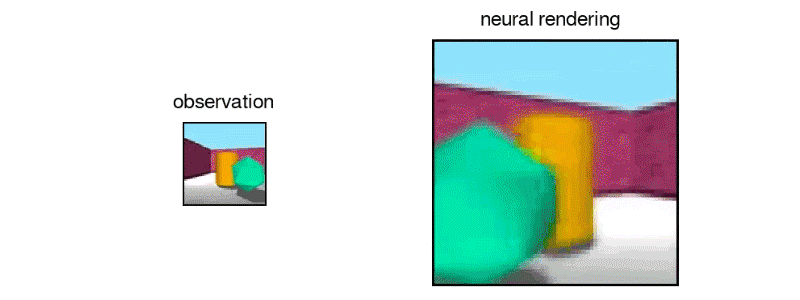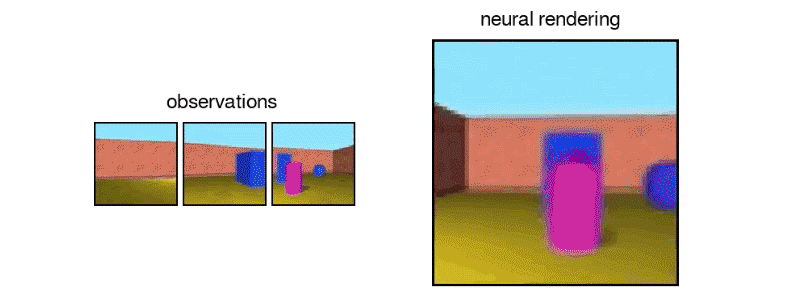
该网络可以对其看不到的地区进行有根据的猜测
在训练过程中,神经网络提供了多个图像,每个图像来自具有相似特征的一堆不同“房间”。在一个实验中,团队生成了一组包含多个几何形状(如球体,立方体和锥体)的程式化方形“房间”。每个房间也有随机选择的光源和墙壁颜色和纹理。由于网络是通过来自多个“房间”的数据进行培训的,因此它必须设法以一种通用的方式来表示房间内容。
一旦GQN得到训练,就可以从一个以前从未见过的新“房间”提供一个或多个图像。(小程序开发,找昱远科技)经过一系列具有类似特征的其他房间的训练后,该网络对房间的正常外观有一个很好的直觉,因此能够对房间中不直接可见的部分进行有根据的猜测。
DeepMind
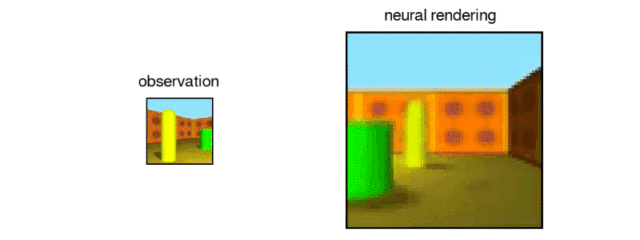
例如,GQN可以预测墙上的重复图案可能会继续在被其他物体遮挡的部分墙上。它可以预测场景中的物体如何在墙壁,地板和其他物体上投射阴影。而且,这一切都没有研究人员对光的物理或被分析场景的特征进行任何明确的规定。
“它可以学习我们不知道如何手工学习的东西,”Eslami告诉我们。“桌子通常位于椅子旁边的事实 – 这是我们直觉知道的事情,但很难量化和编码,神经网络可以学习,就像学习物体投(小程序开发,找昱远科技)下阴影一样。”
换句话说,假设一个GQN是用一堆家庭内部的图像进行训练的,然后从之前没有见过的房子给出图像。如果可用的图像只显示餐桌的一半,网络可能会弄清楚桌子另一半的样子 – 并且桌子旁边可能有椅子。如果一间卧室的楼上有一间房间,但其内部不在其中一个图像中,网络可能会猜测它内部会有一张床和一个梳妆台。
这不是因为网络对桌子和椅子或床是什么概念性的理解。简单地说,从统计学的角度来看,桌子形状的物体倾向于在其旁边有椅子形状的物体,而卧室形状的房间倾向于在其内部具有床形物体。
生成查询网络具有很高的通用性
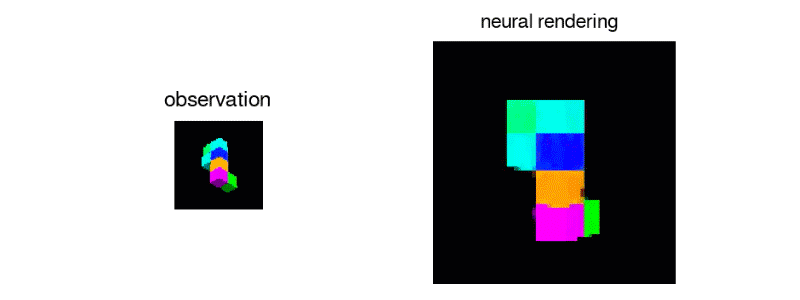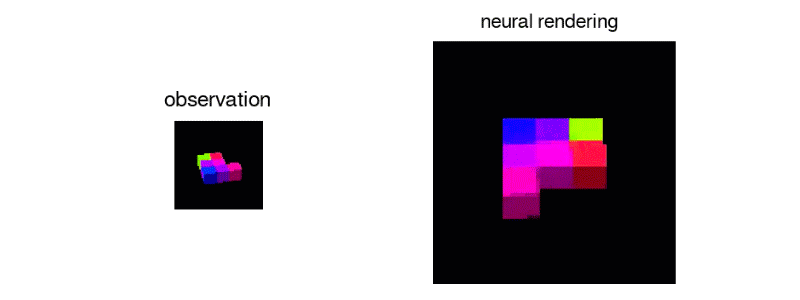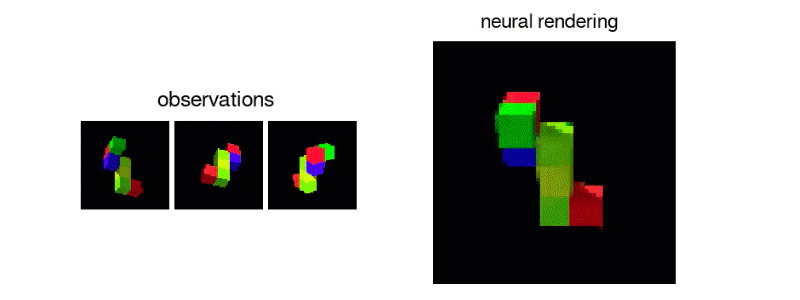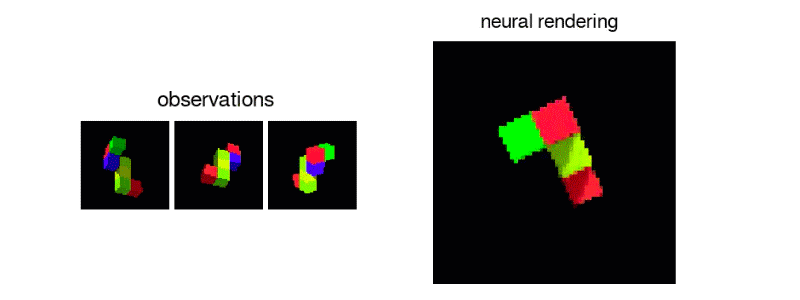
DeepMind团队构建的网络可以从数量非常有限的数据中获得丰富的推论。在另一项实验中,研究人员通过向网络展示一堆随机生成的形状来训练网络,这些形状看起来像三维俄罗斯方块。在训练过程中,网络显示了一系列不同的随机生成的片段,每个片段有几个图像。
一旦网络被训练,研究人员就给网络一个新的俄罗斯方块形状的图像,这是以前从未见过的。从这张单张照片中,网络常常能够从任何其他角度生成逼真的三维图像:
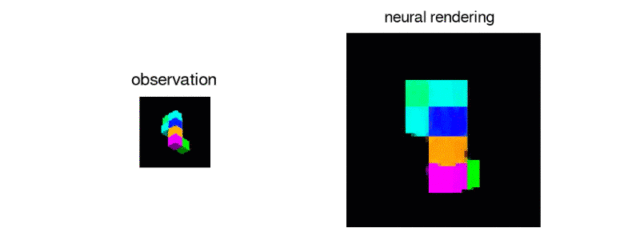
当然,这并不总是可能的。如果单个示例图像是从某个片段的某个片段被隐藏的角度拍摄的,则网络无法知道被遮挡的片段是什么样子。在这种情况下,网络将随机生成与观察到的图像部分一致的许多形状之一。但是,如果所有片段在示例图像中都可见,则网络非常适合推断片的形状并从任何角度呈现其图像。
GQN可以处理令人惊讶的复杂场景。在另一个实验中,研究人员构建了三维迷宫,看起来有点像微型厄运水平。由于这些虚拟环境具有多个房间和通道,因此没有任何一个图像可以显示整个环境的一小部分。但是如果它给出了一个新的迷宫的六张快照,GQN能够组装一个整个迷宫的精确模型 – 或者至少是那些至少在一个图像中显示的(小程序开发,找昱远科技)那些部分。